

The Economics of Autonomous Workflows: Budgeting for the AI Era
As businesses transition from traditional SaaS tools to custom automated ecosystems, the financial conversation is shifting. In 2026, the question is no longer about "software licenses" but about "infrastructure efficiency." For organizations looking to move away from expensive, per-seat legacy platforms, calculating the n8n Implementation Cost has become a critical step in their digital transformation roadmap.
The Rise of Open-Source Orchestration
The shift toward AI agents requires a flexible "brain" that can connect various APIs, databases, and Large Language Models (LLMs). n8n has emerged as the leading choice for this orchestration because of its "fair-code" model, which allows for self-hosting. Unlike closed-loop competitors that charge per execution, n8n provides a predictable environment where the cost is tied to your own hardware and compute resources rather than a vendor's arbitrary pricing tiers.
However, "self-hosted" does not mean "free." A professional-grade setup requires a well-planned AI Agent Infrastructure Budget to ensure that as your agents scale, your server doesn't crash under the weight of high-volume data processing.
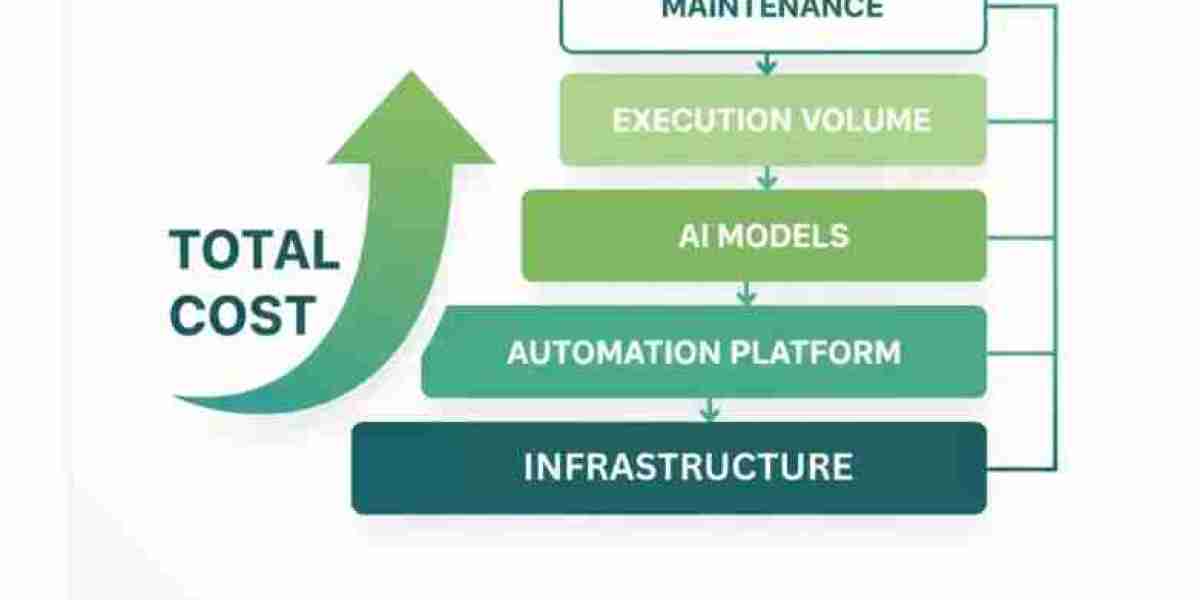
Breaking Down the Cost Pillars
To build a sustainable AI-driven business unit, you must look beyond the initial setup and consider the total cost of ownership (TCO). A robust budget typically consists of three primary layers:
- Compute and Hosting
This is the physical or virtual foundation where your workflows live. Depending on your needs, you might choose:
- Virtual Private Servers (VPS): Reliable and scalable, usually costing between $20 to $100 per month depending on RAM and CPU requirements.
- Cloud-Native Clusters: For enterprise-scale operations involving thousands of concurrent executions.
- Edge Computing: If low latency is a priority for real-time customer interactions.
- LLM Token Consumption
Your AI agents need "fuel" to think. This fuel comes in the form of tokens from providers like OpenAI, Anthropic, or local open-source models via Ollama.
- Input Tokens: The data you send to the AI (context).
- Output Tokens: The AI's response.
In a high-frequency workflow, token costs can quickly become the largest line item in your budget if not managed with efficient prompt engineering and caching strategies.
- Maintenance and Monitoring
An AI agent is not a "set it and forget it" tool. API endpoints change, prompts need "drift" monitoring, and workflows require error-handling logic. Investing in a developer or an agency to manage these technical nuances is a necessary part of a long-term strategy.
CRM vs. n8n: A Financial Comparison
The primary motivation for many companies moving toward n8n is the "Seat Tax" found in traditional CRMs. In a legacy system, adding five new employees means paying for five new licenses. In an n8n-powered infrastructure, adding new employees often costs nothing extra because the work is being performed by agents in the background.
Expense Category | Traditional CRM Model | AI Agent (n8n) Model |
Licensing | Per Seat / Per Month | Fixed Infrastructure Cost |
Data Scaling | Extra charge for more leads | Managed by Database/Storage |
Customization | Paid Add-ons / Consultants | Open-Source / Flexible API |
Predictability | High (Monthly recurring) | Variable (Usage-based tokens) |
Strategic Optimization for AI Workflows
To keep your AI Agent Infrastructure Budget under control, it is essential to implement "Agentic Governance." This means setting hard caps on API usage and using smaller, specialized models for simple tasks (like data cleaning) while reserving expensive models (like GPT-4o or Claude 3.5 Sonnet) for complex reasoning tasks.
By layering your intelligence, you can reduce costs by up to 60% without sacrificing performance. Furthermore, utilizing n8n’s ability to run on-premise allows businesses to keep sensitive data within their own firewall, potentially saving thousands in cybersecurity insurance and compliance audit costs.
Looking Ahead: The ROI of Autonomy
The return on investment for an n8n Implementation Cost is measured in "Hours Reclaimed." When an AI agent handles lead qualification, document parsing, and follow-up emails, your human team is freed to focus on high-value strategy and relationship building.
For businesses operating in 2026, the transition to AI-first automation is no longer a luxury—it is a survival mechanism. Those who budget correctly today will possess a massive competitive advantage in operational speed and profit margins tomorrow.
Practical Implementation Steps:
- Audit Current Manual Tasks: Identify where employees spend more than 5 hours a week on data entry.
- Select a Hosting Tier: Start with a modest VPS and scale as your workflow complexity grows.
- Monitor Token Spend: Use dashboards to track which workflows are consuming the most resources.
For a granular breakdown of server specifications and token estimation calculators, read the full guide at Fatcamel.ai.






